Remove Duplicates from Sorted List II
Question
- leetcode: Remove Duplicates from Sorted List II | LeetCode OJ
- lintcode: (113) Remove Duplicates from Sorted List II
Given a sorted linked list, delete all nodes that have duplicate numbers,
leaving only distinct numbers from the original list.
Example
Given 1->2->3->3->4->4->5, return 1->2->5.
Given 1->1->1->2->3, return 2->3.
題解
上題為保留重複值節點的一個,這題刪除全部重複節點,看似區別不大,但是考慮到鏈表頭不確定(可能被刪除,也可能保留),因此若用傳統方式需要較多的if條件語句。這裏介紹一個處理鏈表頭節點不確定的方法——引入dummy node.
ListNode *dummy = new ListNode(0);
dummy->next = head;
ListNode *node = dummy;
引入新的指標變數dummy,並將其next變數賦值為head,考慮到原來的鏈表頭節點可能被刪除,故應該從dummy處開始處理,這裏複用了head變數。考慮鏈表A->B->C,刪除B時,需要處理和考慮的是A和C,將A的next指向C。如果從空間使用效率考慮,可以使用head代替以上的node,含義一樣,node比較好理解點。
與上題不同的是,由於此題引入了新的節點dummy,不可再使用node->val == node->next->val,原因有二:
- 此題需要將值相等的節點全部刪掉,而刪除鏈表的操作與節點前後兩個節點都有關系,故需要涉及三個鏈表節點。且刪除單向鏈表節點時不能刪除當前節點,只能改變當前節點的
next指向的節點。 - 在判斷val是否相等時需先確定
node->next和node->next->next均不為空,否則不可對其進行取值。
說多了都是淚,先看看我的錯誤實現:
C++ - Wrong
/**
* Definition of ListNode
* class ListNode {
* public:
* int val;
* ListNode *next;
* ListNode(int val) {
* this->val = val;
* this->next = NULL;
* }
* }
*/
class Solution{
public:
/**
* @param head: The first node of linked list.
* @return: head node
*/
ListNode * deleteDuplicates(ListNode *head) {
if (head == NULL || head->next == NULL) {
return NULL;
}
ListNode *dummy;
dummy->next = head;
ListNode *node = dummy;
while (node->next != NULL && node->next->next != NULL) {
if (node->next->val == node->next->next->val) {
int val = node->next->val;
while (node->next != NULL && val == node->next->val) {
ListNode *temp = node->next;
node->next = node->next->next;
delete temp;
}
} else {
node->next = node->next->next;
}
}
return dummy->next;
}
};
錯因分析
錯在什麼地方?
- 節點dummy的初始化有問題,對class的初始化應該使用
new - 在else語句中
node->next = node->next->next;改寫了dummy-next中的內容,返回的dummy-next不再是隊首元素,而是隊尾元素。原因很微妙,應該使用node = node->next;,node代表節點指標變數,而node->next代表當前節點所指向的下一節點地址。具體分析可自行在紙上畫圖分析,可對指標和鏈表的理解又加深不少。
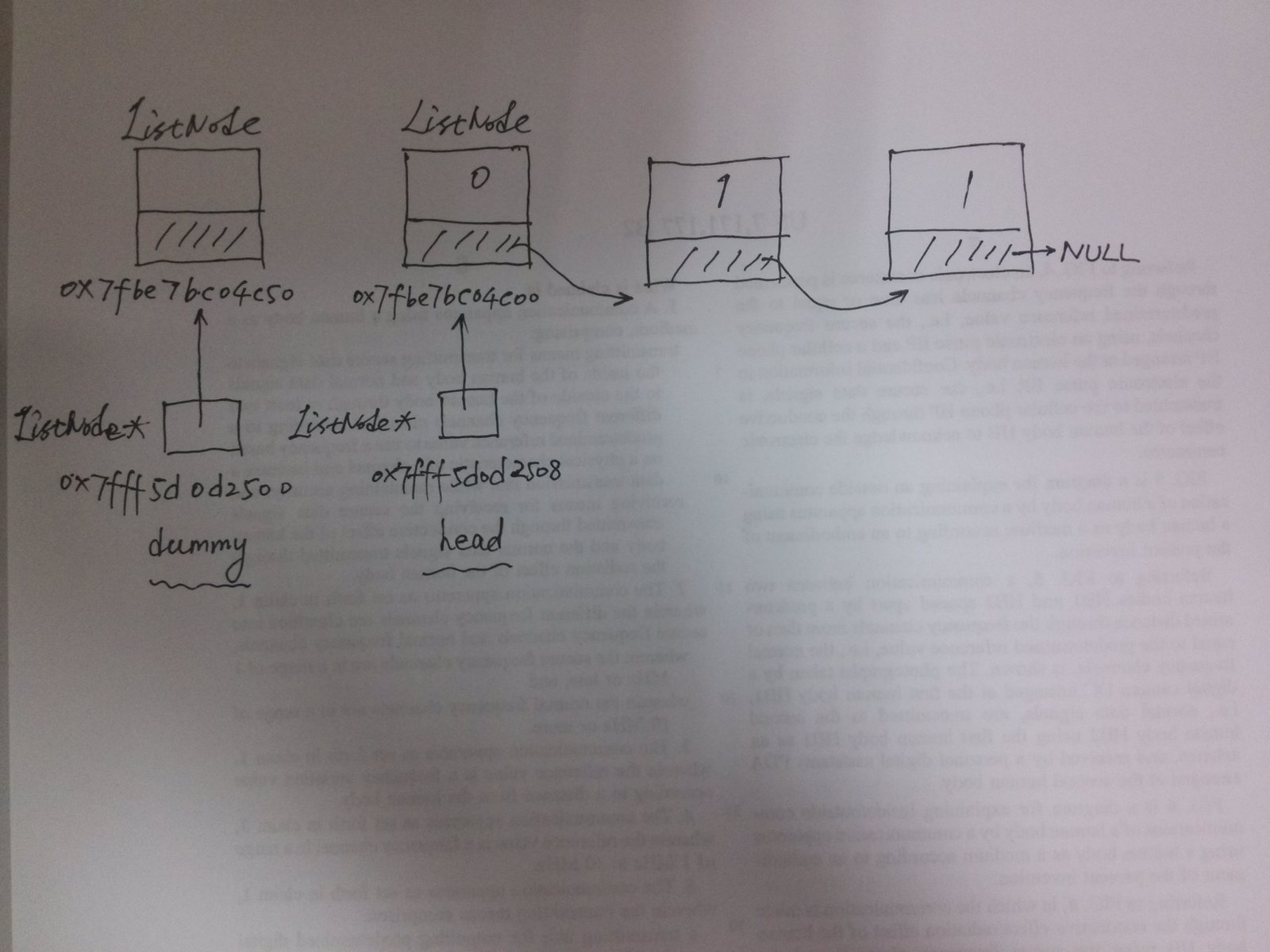
圖中上半部分為ListNode的記憶體示意圖,每個框底下為其內存地址。dummy指標本身的地址為ox7fff5d0d2500,其保存著指標值為0x7fbe7bc04c50. head指標本身的地址為ox7fff5d0d2508,其保存著指標值為0x7fbe7bc04c00.
好了,接下來看看正確實現及解析。
Python
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution:
# @param {ListNode} head
# @return {ListNode}
def deleteDuplicates(self, head):
if head is None:
return None
dummy = ListNode(0)
dummy.next = head
node = dummy
while node.next is not None and node.next.next is not None:
if node.next.val == node.next.next.val:
val_prev = node.next.val
while node.next is not None and node.next.val == val_prev:
node.next = node.next.next
else:
node = node.next
return dummy.next
C++
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
if (head == NULL) return NULL;
ListNode *dummy = new ListNode(0);
dummy->next = head;
ListNode *node = dummy;
while (node->next != NULL && node->next->next != NULL) {
if (node->next->val == node->next->next->val) {
int val_prev = node->next->val;
// remove ListNode node->next
while (node->next != NULL && val_prev == node->next->val) {
ListNode *temp = node->next;
node->next = node->next->next;
delete temp;
}
} else {
node = node->next;
}
}
return dummy->next;
}
};
Java
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
public class Solution {
public ListNode deleteDuplicates(ListNode head) {
if (head == null) return null;
ListNode dummy = new ListNode(0);
dummy.next = head;
ListNode node = dummy;
while(node.next != null && node.next.next != null) {
if (node.next.val == node.next.next.val) {
int val_prev = node.next.val;
while (node.next != null && node.next.val == val_prev) {
node.next = node.next.next;
}
} else {
node = node.next;
}
}
return dummy.next;
}
}
源碼分析
- 首先考慮異常情況,head 為 NULL 時返回 NULL
- new一個dummy變數,
dummy->next指向原鏈表頭。 - 使用新變數node並設置其為dummy頭節點,遍歷用。
- 當前節點和下一節點val相同時先保存當前值,便於while循環終止條件判斷和刪除節點。注意這一段代碼也比較精煉。
- 最後返回
dummy->next,即題目所要求的頭節點。
Python 中也可不使用is not None判斷,但是效率會低一點。
複雜度分析
兩個指標(node.next 和 node.next.next)遍歷,時間複雜度為 . 使用了一個 dummy 和中間緩存變數,空間複雜度近似為 .
Reference
results matching ""
powered by 